

How To Filter Rows In Pandas Dataframe Using Regex
Filter a Pandas DataFrame by a Partial String or Pattern in 8 Ways
How to audit a DataFrame and return merely the desired rows

Filtering a DataFrame refers to checking its contents and returning merely those that fit certain criteria. Information technology is part of the data assay job known as data wrangling and is efficiently washed using the Pandas library of Python.
The thought is that once yous accept filtered this data, you lot tin can clarify it separately and gain insights that might be unique to this group, and inform the predictive modeling steps of the project moving forward.
In this commodity, we will use functions such every bit Series.isin() and Series.str.contains() to filter the data. I minimized the use of apply() and Lambda functions which apply more code and are disruptive to many people including myself. Nonetheless, I will explain the code and include links to related articles.
We will use the Netflix dataset from Kaggle which contains details of Goggle box shows and movies including the title, managing director, the bandage, age rating, year of release, and duration. Let u.s. now import the required libraries and load the dataset into our Jupyter notebook.
import pandas as pd data = pd.read_csv('netflix_titles_nov_2019.csv') information.head()

i. Filter rows that match a given Cord in a cavalcade
Here, nosotros desire to filter by the contents of a particular column. We will use the Series.isin([list_of_values] ) role from Pandas which returns a 'mask' of Truthful for every element in the column that exactly matches or False if information technology does not match any of the listing values in the isin() office. Note that you must e'er include the value(due south) in foursquare brackets even if it is only one.
mask = data['type'].isin(['TV Show']) #display the mask
mask.head()

We then apply this mask to the whole DataFrame to render the rows where the status was True. Note how the index positions where the mask was True above are the only rows returned in the filtered DataFrame below.
#Brandish start five rows
#of the filtered data data[mask].head()
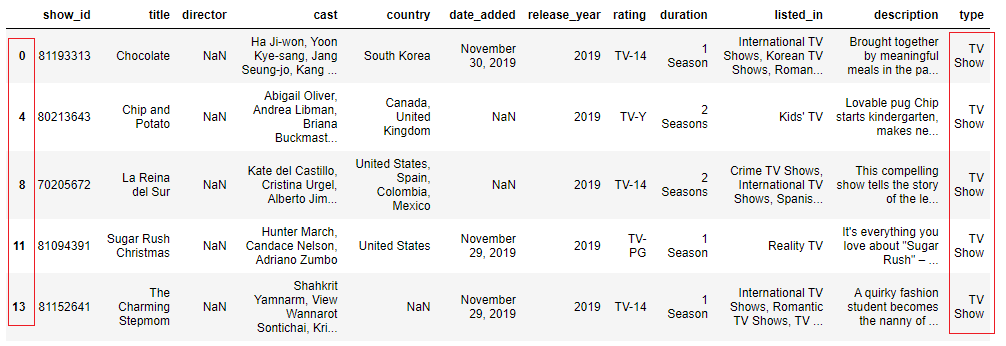
Note: df.loc[mask] generates the aforementioned results equally df[mask]. This is especially useful when you want to select a few columns to brandish.
data.loc[mask, ['title','state','duration']] 
Other means to generate the mask above;
- If you do non want to bargain with a mix of upper and lowercase messages in the
isin()function, first convert all the column's elements into lowercase.
mask = data['blazon'].str.lower().isin(['tv show']) - We can also use the == equality operator which compares if two objects are the same. This will compare whether each element in a column is equal to the string provided.
mask = (data['blazon'] == 'TV Bear witness') - We can provide a list of strings like
isin(['str1','str2'])and check if a column'due south elements match any of them. The two masks beneath return the same results.
mask = information['type'].isin(['Motion picture','TV Show']) #or mask = (data['type'] == 'Picture') | (data['blazon'] == 'Boob tube Show')
The mask returned will exist all Trues because the 'type' column contains only 'Picture' and 'TV Show' categories.
two. Filter rows where a partial string is nowadays
Here, we want to bank check if a sub-string is present in a column.
For example, the 'listed-in' column contains the genres that each moving picture or show belongs to, separated by commas. I want to filter and return only those that take a 'horror' element in them because right now Halloween is upon us.
We volition use the string method Series.str.contains('pattern', example=False, na=False) where 'design' is the substring to search for, and instance=False implies case insensitivity. na=Imitation means that any NaN values in the column will be returned every bit False (pregnant without the pattern) instead of as NaN which removes the boolean identity from the mask.
mask = data['listed_in'].str.contains('horror', case=Simulated, na=False) We will then employ the mask to our data and display three sample rows of the filtered dataframe.
information[mask].sample(3) 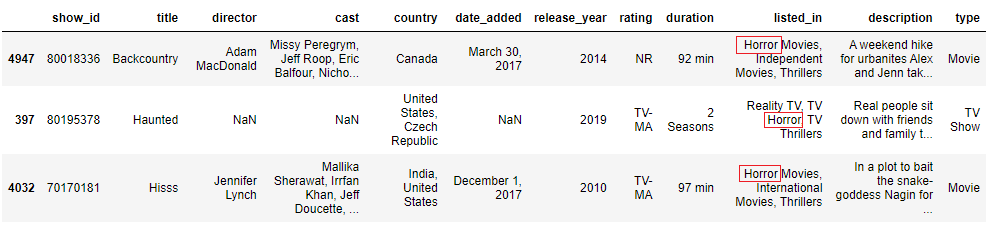
Other examples:
- We can also check for the presence of symbols in a column. For example, the
'bandage'column contains the actors separated by commas, and we tin can check for rows where at that place is only one actor. This is by checking for rows with a comma (,) and then applying the filtering mask to the information using a tilde (~) to negate the statement.
mask = data['cast'].str.contains(',', na=False) data[~mask].head()

Only now these results have NaNs because we used na=False and the tilde returns all rows where the mask was Faux. We volition employ df.dropna(axis=0, subset='cast)to the filtered data. Nosotros use centrality=0 to mean row-wise because we want to drop the row not the column. subset=['cast'] checks only this column for NaNs.
data[~mask].dropna(axis=0, subset=['cast']) 
Note: To check for special characters such equally + or ^, use regex=False (the default is Truthful) so that all characters are interpreted equally normal strings not regex patterns. You tin alternatively employ the backslash escape character.
df['a'].str.contains('^', regex=False) #or df['a'].str.contains('\^')
iii. Filter rows with either of two fractional strings (OR)
You tin can check for the presence of whatsoever two or more strings and return Truthful if whatsoever of the strings are present.
Allow u.s.a. check for either 'horrors' or 'stand-upwards comedies' to complement our emotional states later each picket.
We employ str.contains() and pass the two strings separated past a vertical bar (|) which means 'or'.
design = 'horror|stand-upwards' mask = data['listed_in'].str.contains(blueprint, example=Faux, na=Imitation) data[mask].sample(3)
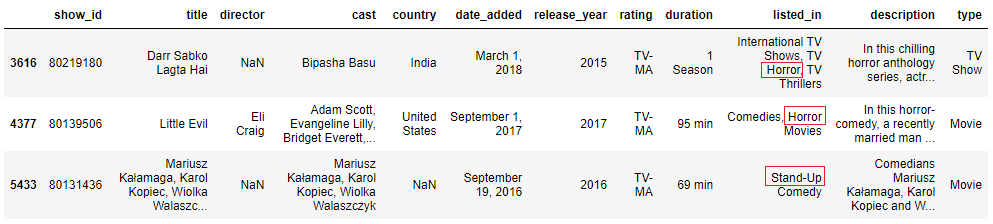
- Nosotros can also use the long-course where we create two masks and pass them into our data using
|.

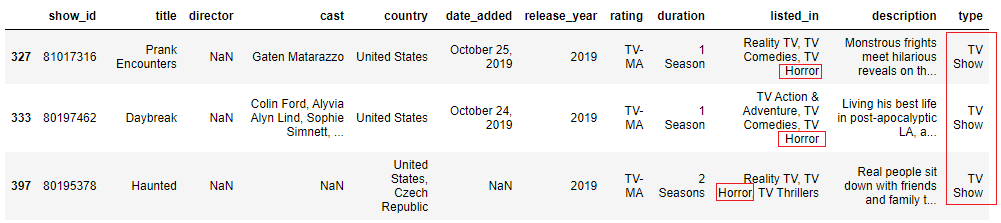
Annotation: You tin create many masks and pass them into the information using the symbols | or & . The & ways combine the masks and render True where both masks are True, while | means render True where any of the masks is Truthful.
mask1 = (information['listed_in'].str.contains('horror', instance=False, na=False)) mask2 = (data['type'].isin(['Goggle box Show'])) data[mask1 & mask2].caput(iii)
4. Filter rows where both strings are present (AND)
Sometimes, we want to cheque if multiple sub-strings appear in the elements of a column.
In this example, nosotros will search for movies that were filmed in both United states of america and Mexico countries.
- The code
str.contains('str1.*str2')uses the symbols.*to search if both strings appear strictly in that gild, wherestr1must appear first to return True.
pattern = 'states.*mexico' mask = data['country'].str.contains(design, case=False, na=Faux) information[mask].head()
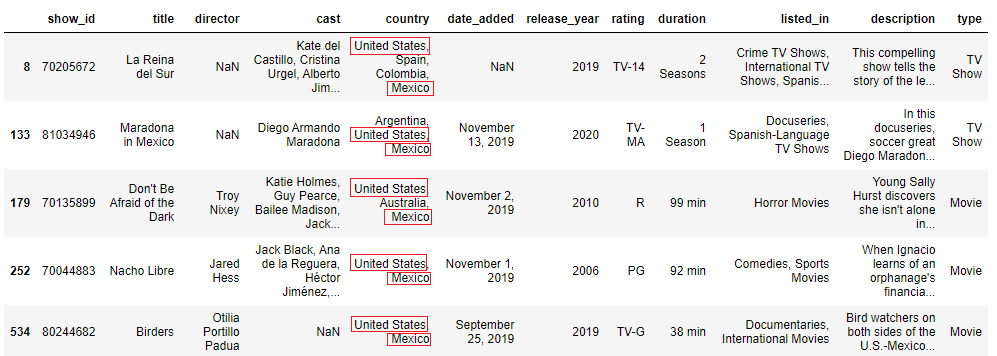
Note how 'United States' always appears first in the filtered rows.
- Where the order does not matter (Mexico can announced first in a row), use
str.contains('str1.*str2|str2.*str1').The|ways 'return rows wherestr1appears first, orstr2appears start'.
pattern = 'states.*mexico|mexico.*states' mask = data['land'].str.contains(pattern, case=Imitation, na=False) data[mask].head()
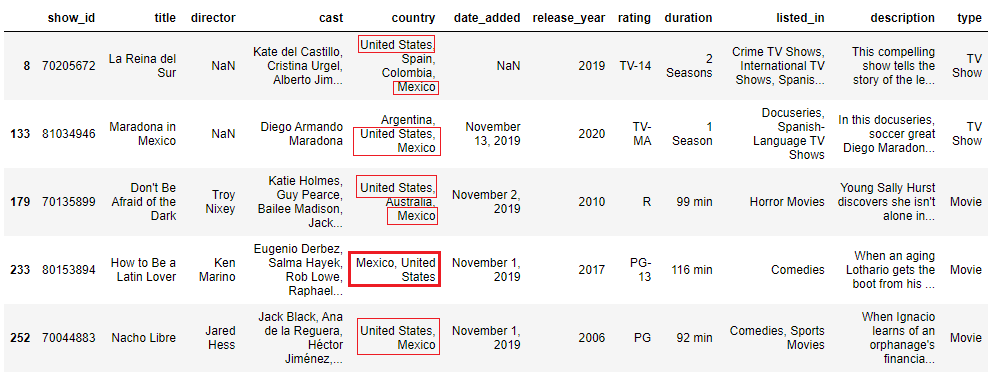
See how in the 4th row 'Mexico' appears first.
- You can besides create a mask for each country, then laissez passer the masks into the data using
&symbol. The code below displays the same DataFrame as higher up.
mask1 = (data['country'].str.contains('states', example=False, na=False))
mask2 = (data['country'].str.contains('mexico', case=False, na=Fake)) data[mask1 & mask2].head()
5. Filter rows with numbers in a particular column
Nosotros might also desire to cheque for numbers in a cavalcade using the regex blueprint '[0–ix]'. The code looks like str.contains('[0–9]').
In the next case, nosotros want to cheque the historic period rating and return those with specific ages after the dash such equally TV-14, PG-13, NC-17 and leave out Boob tube-Y7 and Idiot box-Y7-FV. Nosotros, therefore, add a dash (-) before the number blueprint.
blueprint = '-[0-ix]' mask = data['rating'].str.contains(pattern, na=False)information[mask].sample(3)
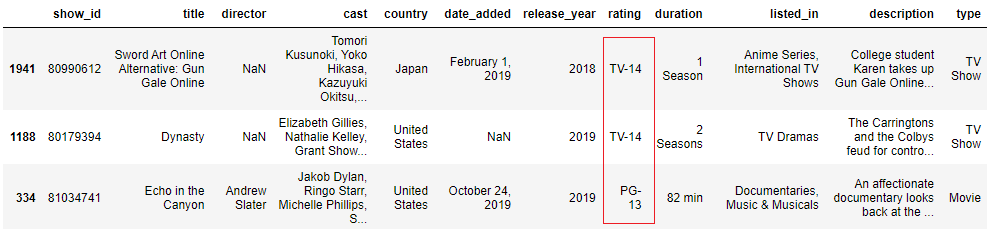
half-dozen. Filter rows where a partial cord is present in multiple columns
Nosotros can check for rows where a sub-cord is present in 2 or more given columns.
- For example, let u.s.a. check for the presence of 'tv' in iii columns (
'rating','listed_in'and'type') and return rows where it'south present in all of them. The easiest way is to create 3 masks each for a specific column, and filter the information using&symbol meaning 'and' (use | symbol to return True if information technology'southward in at least 1 column).
mask1 = data['rating'].str.contains('tv', case=False, na=Simulated) mask2 = information['listed_in'].str.contains('tv set', case=False, na=False) mask3 = information['type'].str.contains('television receiver', case=False, na=Fake) data[mask1 & mask2 & mask3].head()
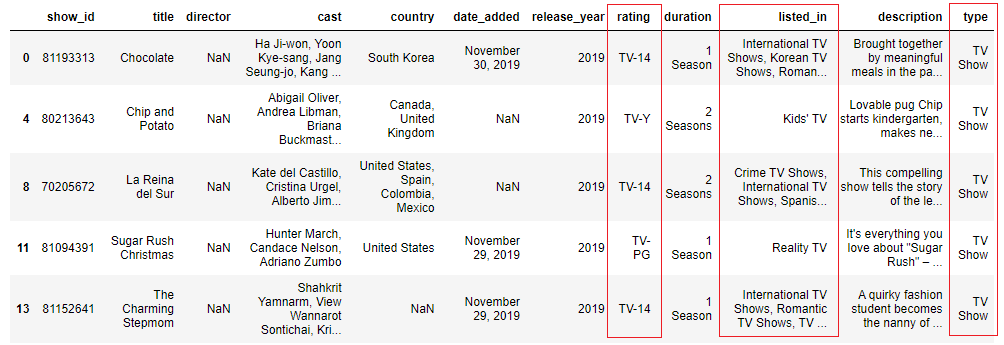
See how 'idiot box' is present in all three columns in the filtered data to a higher place.
- Another way is using the slightly complicated utilise() and Lambda functions. Read the commodity Lambda Functions with Practical Examples in Python for clarity on how these two functions work.
cols_to_check = ['rating','listed_in','blazon'] pattern = 'tv' mask = data[cols_to_check].apply(
lambda col:col.str.contains(
pattern, na=Faux, instance=False)).all(centrality=1)
The code for the mask above says that for every column in the listing cols_to_check, apply str.contains('tv') office. It then uses .all(axis=i) to consolidate the three masks into i mask (or column) by returning True for every row where all the columns are Truthful. (employ .whatever() to return True for presence in at-least 1 column).

The filtered DataFrame is the aforementioned as the one displayed previously.
vii. Filter for rows where values in one column are present in another column.
Nosotros can check whether the value in one cavalcade is present equally a fractional string in another column.
Using our Netflix dataset, let the states check for rows where the 'director' also appeared in the 'cast' every bit an actor.
In this example, nosotros will use df.employ(), lambda, and the 'in' keyword which checks if a certain value is present in a given sequence of strings.
mask = data.apply(
lambda x: str(x['managing director']) in str(10['cast']),
axis=one) df.use()above holds a lambda function which says that for every row (x), check if the value in 'director' is nowadays in the 'cast' cavalcade and return Truthful or False. I wrapped the columns with str() to catechumen each value into a String because it raised a TypeError probably because of NaNs. We use axis=i to mean column-wise, therefore the operation is done for every row and the consequence will exist a column (or series).
data[mask].head() 
Whoops! That's a lot of NaNs. Let'south drop them using the director's column as the subset and brandish afresh.
data[mask].dropna(subset=['manager']) 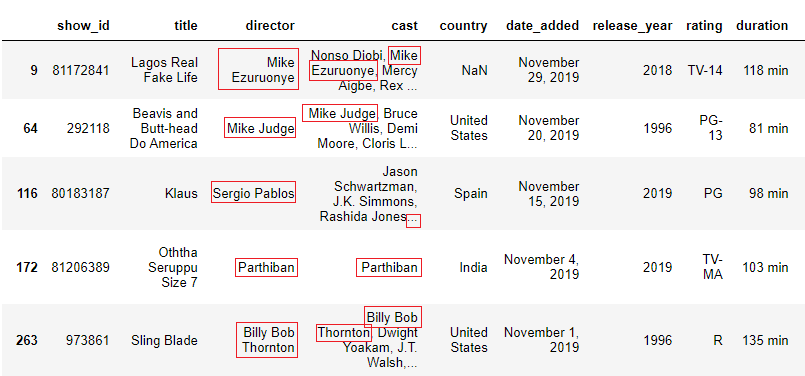
For other ways to check if values in i column match those in another, read this article.
viii. Checking cavalcade names (or index values) for a given sub-string
We can check for the presence of a partial string in cavalcade headers and return those columns.
Filter cavalcade names
- In the case below, we will use
df.filter(like=pattern, axis=1)to render column names with the given pattern. We can also employaxis=columns. Note that this returns the filtered information and no mask is generated.
data.filter(like='in', axis=ane) 
- Nosotros can also use
df.locwhere nosotros display all the rows but merely the columns with the given sub-string.
information.loc[:, data.columns.str.contains('in')] This code generates the same results similar the prototype above. Read this article for how .loc works.
Filter by index values
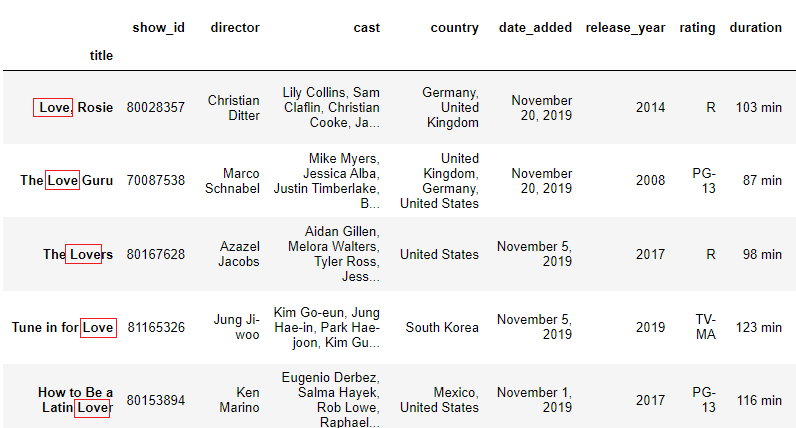
Let u.s.a. first set up the championship every bit the index, then filter by the discussion 'Dear'. We will use the same methods as above with slight adjustments.
Utilize df.filter(similar='Dearest', centrality=0) . Nosotros can also use centrality=index.
df = data.set_index('title') df.filter(similar='Love', centrality=0)
Utilize df.loc[] to display the aforementioned results as higher up. Here we cull the desired rows in the first role of.loc and return all columns in the 2d part.
df.loc[df.index.str.contains('Beloved'), :] Other filtering methods
- Using the pandas query() function
This is a data filtering method peculiarly favored by SQL ninjas. The syntax is df.query('expression') and the effect is a modified DataFrame. The cool affair is that aside from filtering by individual columns as we've done earlier, y'all tin reference a local variable and call methods such as mean() inside the expression. It also offers functioning advantages to other circuitous masks.
#Example
data.query('country == "South Africa"') 
I rarely apply this approach myself, simply many people notice it simpler and more readable. I encourage you to explore more as it has compelling advantages. This and this manufactures are a adept place to start.
- Using other string (Series.str.) example functions
These methods can too filter data to return a mask
-
Series.str.len() > 10 -
Series.str.startswith('Nov') -
Series.str.endswith('2019') -
Series.str.isnumeric() -
Series.str.isupper() -
Series.str.islower()
Determination
As a data professional, chances are you will often need to carve up information based on its contents. In this article, we looked at 8 ways to filter a DataFrame by the string values present in the columns. We used Pandas, Lambda functions, and the 'in' keyword. Nosotros besides used the | and & symbols, and the tilde (~) to negate a argument.
We learned that these functions return a mask (a column) of True and False values. We and then laissez passer this mask into our DataFrame using square brackets like df[mask] or using the .loc function similar df.loc[mask]. You can download the total code hither from Github.
I promise you enjoyed the article. To receive more similar these whenever I publish a new ane, subscribe hither. If you are not notwithstanding a medium fellow member and would like to support me as a author, follow this link and I will earn a small committee. Cheers for reading!
References
10 Means to Filter Pandas DataFrame
Python Pandas String Operations— Working with Text Data
Select by partial string from a pandas DataFrame

How To Filter Rows In Pandas Dataframe Using Regex,
Source: https://towardsdatascience.com/8-ways-to-filter-a-pandas-dataframe-by-a-partial-string-or-pattern-49f43279c50f
Posted by: jacquespueed1957.blogspot.com
0 Response to "How To Filter Rows In Pandas Dataframe Using Regex"
Post a Comment